Writing a Unix-like Operating System: Part 1
2025-09-29
Scroll to commentsScope: To build an operating system kernel that runs on real hardware (my Dell Inspiron 13 5330) resembling an early console-based Unix (such as Sixth Edition Research Unix) in kernel functionality.
This post documents my progress in building a Unix-like operating system for the x86-64 platform. It contains a brief overview of the state at the time of writing, followed by more technical discussion of the design decisions I've made. The source code for this operating system is available here.
This OS is still a work in progress, and is missing some key Unix features:
- Signals
- Persistent filesystem
- Working directory and relative paths in system calls
- Environment variables
- Many system calls pertaining to creation and deletion of files and directories
This kernel is currently highly unstable, and tends to crash. There is much work to be done on error handling.
I plan to write about these features in a Part 2, once I have implemented them.
Overview
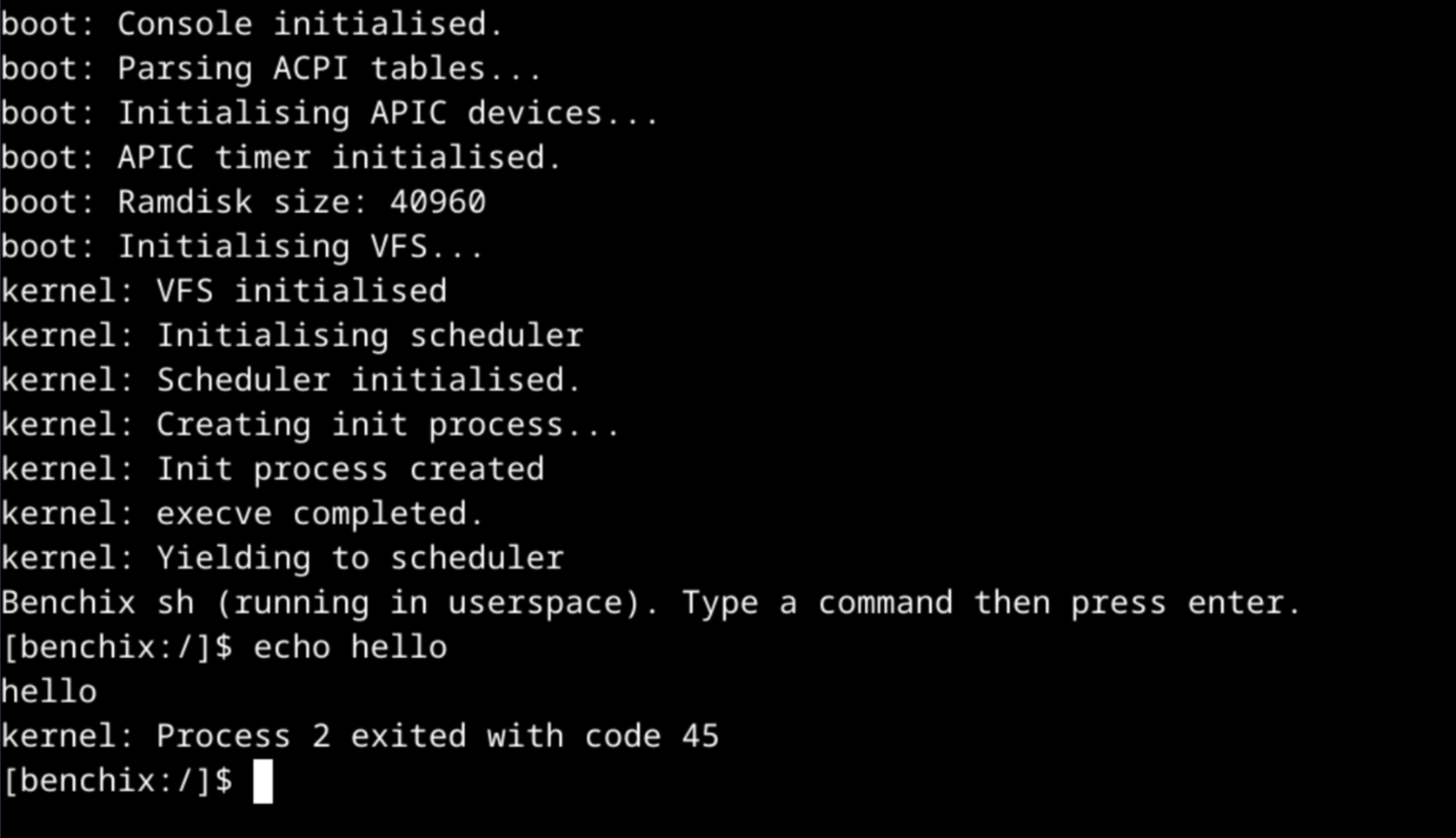
To learn more about modern operating systems, I've built an OS kernel for the x86-64 platform (also known as AMD64). It is written in the Rust programming language, and runs on bare-metal. Current features:
- A simple userspace shell
- A kernel-mode text console device (controlled by reading and writing to
/dev/console) - A rudimentary VFS (Virtual file system) supporting different file systems
(including a device file system which contains
/dev/console) under a single root file system - A subset of Linux syscalls following Linux syscall calling conventions
- Loading of static 64-bit ELF executables.
- Preemptive multitasking on a single processor
fork()andexec()based process spawning- Drivers for the GOP framebuffer (the graphical interface provided by the UEFI firmware), the APIC interrupt controller, and for the emulated PS2 keyboard connected through the IOAPIC
A detailed explanation of these features will follow.
References
- OSDev Wiki
- Intel® 64 and IA-32 Architectures Software Developer's Manual
- Linux syscall reference | x64.syscall.sh
- Linux man pages (eg:
man 2 read) - Philipp Oppermann's blog | Writing an OS in Rust
- Wesley Aptekar-Cassels | How to set up the APIC to get keyboard interrupts
- System V ABI
- mit-pdos/xv6-public: xv6 OS
- redox-os / kernel
- Linux kernel UAPI headers
- Operating Systems: Three Easy Pieces
- Rust-OS Kernel - To userspace and back! - nikofil’s blog
- Malloc tutorial
Previous attempts
This is not my first attempt at building an OS. Soon after learning Rust in December 2022, I came across Philipp Oppermann's excellent Rust OS tutorial series, which was my initial exposure to OS development. The series provides a thorough walkthrough of the initial setup process of creating an OS for x86-64 (including text output, interrupts, paging and heap allocation). This lead me to several attempts at creating an operating system:
- bench: An x86-64 C kernel using Limine bootloader (BIOS-only)
- In this project I applied what I had learned from the Rust tutorials in a different context
- Most progress here was with understanding interrupts with the IDT (Interrupt Descriptor Table) and the legacy 8259 Programmable Interrupt Controller
- bench2: An x86-64 Rust kernel using the
bootloadercrate with support for UEFI booting.- In this project, I mostly followed the Rust tutorials for implementing core structures (IDT, GDT, page table, heap), but focused on getting keyboard support on UEFI. At the time of this writing, the Rust OS tutorials rely on some functionality only available when booting from the legacy BIOS (8259 PIC and VGA text mode), which now have more complex replacements in UEFI. In this attempt, I implemented keyboard input by following overall steps from this post.
Why build a Unix clone?
I started benchix (this project) because I found myself getting stuck on architectural decisions in bench2. As a beginner to OS development, I wanted to focus on the mechanisms of operating systems rather than the policies. This led me to re-scope the project to specifically implement a Unix-like kernel. In benchix, this means a few things:
- A virtual file system allowing devices to be accessed as files
- Unix-like system calls (
read,write,open,close,brk,fork,execve, etc.)
However, benchix isn't a direct port or rewrite of any particular kernel. Where possible, I based my implementation on descriptions of kernel features from man pages or OSTEP (Operating Systems: Three Easy Pieces). The kernels I did reference were xv6 and Redox (linked to in references). I mention areas where my implementation is based on one of these kernels.
Implementation details
This is a roughly chronological record of my implementation, grouped by feature.
The bootloader
The Rust bootloader crate provides a way to create a bootable disk image from a kernel. They have a guide on setting up the two crates needed to boot.
The bootloader provides an entry_point! macro for use in the kernel and will pass a boot_info struct to the annotated function. This contains some important information such as:
- The offset that physical memory is mapped at (memory mappings discussed later)
- A pointer to the GOP framebuffer
- The physical memory layout (used to determine what physical memory frames are available for allocation)
- A pointer to the RSDP. The RSDP is the root pointer to the boot-time ACPI (Advanced Configuration and Power Interface) tables. They are very verbose so I use the
acpicrate to parse these structures. I need this information to set up the interrupt controllers to receive keypresses. - The address the ramdisk is mapped at
The other part of the bootloader crate runs in a build.rs at the root of the workspace. This file builds the C userspace into a .tar archive, and uses Cargo's binary dependency feature to get the kernel binary. Then, it invokes the bootloader crate to create a GPT (GUID Partition Table) disk image.
Framebuffer and panic handling
I use the noto_sans_mono_bitmap crate to display monospaced text on the framebuffer.
I have a separate console (PanicConsole) for kernel panic that does not rely on heap allocated memory. My main console uses a heap-allocated backing text-buffer to hold text to avoid having to read from frame-buffer memory when scrolling (which can be slower). The panic console uses a static mut variable storing a pointer to the buffer and re-initialises the display from there. This is necessary because if the framebuffer was stored behind a lock, the panic handler may deadlock if the panicking thread was holding that lock.
After the heap is available, my main console is initialised from the framebuffer, and it is owned by the boot thread until the initialisation of the VFS. After this it is passed to the device filesystem to be accessed at /dev/console.
IDT and GDT
Initially, I was able to bring over my IDT (interrupt descriptor table) and GDT setup from my old bench2 kernel (which itself matches closely with the Rust OS tutorials).
To manage these structures I use the x86_64 crate, which contains useful
wrappers around Intel 64 registers, structures and instructions. In the original
bench kernel (in C), I implemented some of these by hand, but delegating these
operations to a crate lets me narrow my scope to focusing more on the specifics
of building a kernel (threading, system calls, scheduling, concurrency) rather
than spending time on Intel 64 peculiarities.
I did have to make some modifications for userspace:
- Adding "flat" code and data segment descriptors for userspace (these are mandatory but since I am in Long Mode they don't actually set any segmentation limits).
- The TSS (task state segment, which used to hold the task state in 32-bit mode, but in 64-bit mode now holds the interrupt stack table) gets a new entry (RSP0) to describe the stack to use when an interrupt occurs in Ring 3 (since interrupts are handled in Ring 0). In this case I use the current kernel stack for that thread. If I had one global stack to use for interrupts, then that stack would get overwritten if I do a context switch and then another interrupt occurs. This would mean that the execution would not be able to return to the previous thread, since the return address on the stack would have been overwritten.
Interestingly, long mode supports segmentation for the FS and GS segments. Most kernels use this to store per-processor information (like the current kernel stack). I don't have multiprocessing yet so I have just been using what is effectively a static mut to store this information. However, I will consider using this approach when I add multiprocessing.
Memory management
Bootloader mappings
 Vladsinger, CC BY-SA 3.0, via Wikimedia Commons
Vladsinger, CC BY-SA 3.0, via Wikimedia Commons
{kind=link}
My kernel is a higher-half kernel. On x86-64, there are only 48 usable bits of the virtual address, and the rest are a sign-extension. This essentially breaks the address space into two "halves", which can be distinguished between eachother using only a single bit check. Since virtual address space is so large (256 TiB!), I use the entire higher half for my kernel's memory. This allows syscall handlers to quickly check whether a given buffer belongs to the process, to avoid the process reading the kernel's address space (however, I do not currently mitigate against speculative execution exploits).
The bootloader crate supports configuring the addresses mappings it creates. This saves a bit of work configuring the address-space manually (and the physical offset mappings are needed to actually access the page tables).
pub const HEAP_START: u64 = 0x_ffff_9000_0000_0000;
pub const KERNEL_STACK_START: u64 = 0xffff_f700_0000_0000;
pub const KERNEL_STACK_SIZE: u64 = 80 * 1024; // 80 KiB
pub const LAPIC_START_VIRT: u64 = 0xffff_8fff_ffff_0000;
pub const IOAPIC_START_VIRT: u64 = 0xffff_a000_0000_0000;
pub static BOOTLOADER_CONFIG: BootloaderConfig = {
let mut config = BootloaderConfig::new_default();
config.kernel_stack_size = KERNEL_STACK_SIZE;
config.mappings.kernel_stack = Mapping::FixedAddress(KERNEL_STACK_START);
config.mappings.physical_memory = Some(Mapping::FixedAddress(0xffff_e000_0000_0000));
config.mappings.dynamic_range_start = Some(0xffff_8000_0000_0000);
config.mappings.dynamic_range_end = Some(0xffff_8fff_fffe_ffff);
config
};
This configuration ensures that all kernel mappings created by the bootloader
are in the higher-half. The bootloader is configured to map the entire physical
address space at a fixed offset (0xffff_e000_0000_0000) to allow us to access
the page-tables (which store physical addresses). I have separate mappings for
IOAPIC_START_VIRT and LAPIC_START_VIRT which are used elsewhere to create
no-cache mappings for these memory-mapped interfaces. The dynamic range gives
the bootloader a range to place mappings which I haven't specified (for example
the ramdisk).
Physical Memory Management
The physical memory manager allocates frames of physical memory for the kernel to use. These frames can be then mapped to virtual memory, or used through the physical offset mappings. Apart from the mappings allocated by the bootloader, all mappings are created by allocating one of these frames and creating a virtual address mappings.
One feature my allocator includes that wasn't in the OS tutorials is deallocation. This allows physical frames to be reused after they are done with. This requires the memory manager to keep track of free memory separately from the structures provided by the bootloader. I use a bitmap structure for this:
#[derive(Debug)]
pub struct PhysicalMemoryManager<'a> {
bitmap: &'a mut [u64], // 0 for free, 1 for used
physical_offset: VirtAddr,
}
Each 0 or 1 in the bitmap corresponds to the availability of a 4KiB physical frame, starting at physical address 0 up to the highest physical address.
Creating this structure involves the following process:
- Find the highest address in the bootloader mappings to determine the bitmap size.
- Find the first available memory region in the bootloader mappings that is large enough to store such a bitmap.
- Get a
&'a mut [u64]reference to that region (using the physical offset to get a virtual address to store in the base pointer) and store that as our bitmap. - Mark any reserved regions as used (the bootloader specifies this) as well as marking the frames backing the bitmap as used.
Now, frames can be allocated quite simply:
unsafe impl<'a> FrameAllocator<Size4KiB> for PhysicalMemoryManager<'a> {
fn allocate_frame(&mut self) -> Option<PhysFrame<Size4KiB>> {
for (idx, entry) in self.bitmap.iter().enumerate() {
if *entry != u64::MAX {
let frame = PhysFrame::containing_address(PhysAddr::new(
(idx as u64 * 64 + entry.trailing_ones() as u64) * 4096,
));
self.set_frame(frame);
return Some(frame);
}
}
None
}
}
The advantage of the bitmap approach is its simplicity and memory efficiency. If I wanted faster allocation without searching through the bitmap every time, I could have a frame stack and allocate in bulk, but this is simple enough for now.
Page table management
Here I use the OffsetPageTable from the x86_64 crate to create the actual page table entries to map between a specific page and frame. The OffsetPageTable stores an offset to physical memory, which allows it to access the page table entries through virtual memory.
Kernel Heap
This is another place where I used an external crate. I use the linked_list_allocator crate to implement a GlobalAlloc. This allows me to use Rust's alloc types like Vec and Box. These types do have the disadvantage of having kernel panics when allocation fails.
Virtual File System
- My VFS is informed by James Molloy's Tutorial (archived link)
The virtual file system (VFS) allows for multiple different file systems to be mounted together in a single file system.
My VFS only supports mount points as direct children of the root directory /. This is sufficient to have the two mappings I currently use:
- The device FS mounted at
/dev - The ramdisk mounted at
/bin
Of particular interest is the VFS inode struct:
pub enum FileType {
File,
Directory,
Device, // Just block devices for now, we don't have a good distinction between buffered/unbuffered devices
}
pub struct Inode {
pub dev: u32, // File system that the file belongs to
pub inode: u32, // inode number
pub file_type: FileType,
pub size: usize, // 0 for devices
pub major: Option<u32>, // Device driver
pub minor: Option<u32>, // Specific device that belongs to driver
pub inner: Option<Box<dyn Any + Send + Sync>>,
}
The (dev, inode) tuple uniquely identifies an inode on the file system. The major and minor numbers are used by the device filesystem to identify particular devices, it isn't actually necessary with a VFS but it mirrors the way xv6 does it.
These inodes are the VFS' view of the actual inodes which the drivers retrieve. All of my current filesystems actually store these inodes in memory, but a real persistent file system would retrieve these inodes from the disk. The information stored inside the inode inner field (in persistent filesystems these are usually references to different blocks that form the file) are an implementation detail of the specific driver.
pub trait Filesystem: Send + Sync {
fn open(&self, inode: Arc<Inode>) -> Result<(), FilesystemError>; // Usually increments a reference counter or starts caching inodes -- doesn't lock the file
fn close(&self, inode: Arc<Inode>) -> Result<(), FilesystemError>; // Decrements the reference counter, or removes from cache
fn read(
&self,
inode: Arc<Inode>,
offset: u64,
buffer: &mut [u8],
) -> Result<usize, FilesystemError>; // A locking operation
fn write(
&self,
inode: Arc<Inode>,
offset: u64,
buffer: &[u8],
) -> Result<usize, FilesystemError>; // A locking operation
fn readdir(&self, inode: Arc<Inode>) -> Result<Vec<DirectoryEntry>, FilesystemError>; // Get directory entries
fn inode(&self, dev: u32, inode: u32) -> Result<Arc<Inode>, FilesystemError>; // An inode lookup
fn traverse_fs(&self, root: Arc<Inode>, path: &str) -> Result<Arc<Inode>, FilesystemError> {
... // default implementation omitted for brevity
}
}
The inode() interface allows for retrieving of inodes based on the (dev, inode) pair. It returns an Arc<Inode> which is reference counted. This is useful for persistent file systems where the inodes are not already in memory, because they can be held in a cache and dropped when the reference count goes to 0.
The VirtualFileSystem (which itself implements this trait), allows for mounting of these filesystems. It is initialised as follows:
VFS.init_once(|| {
let mut vfs = VirtualFileSystem::new();
let devfs = Devfs::init(console, 1);
let ramdisk = unsafe { Ramdisk::from_tar(2, &binary) };
vfs.mount(1, Box::new(devfs), "dev", 0).unwrap();
vfs.mount(2, Box::new(ramdisk), "bin", 0).unwrap();
vfs
});
This initialises the /bin filesystem from the uncompressed tar ramdisk loaded into memory by the bootloader, and the /dev filesystem which currently only holds /dev/console (implementing console writes on write, and keyboard input on reads).
Userspace
Relevant reference: Rust-OS Kernel - To userspace and back! - nikofil’s blog
I use the fast system call instructions: SYSCALL and SYSRET to switch between Ring 0 (kernel mode) and Ring 3 (user mode).
Some setup is required before these instructions can be used:
- Enabling system call extensions
- Writing the syscall handler address to the LStar MSR (model‑specific register)
- Specifying that interrupts should be disabled on entry to the system call handler (using the SFMask MSR)
unsafe {
Efer::write(Efer::read() | EferFlags::SYSTEM_CALL_EXTENSIONS);
}
LStar::write(VirtAddr::from_ptr(handle_syscall as *const ()));
SFMask::write(RFlags::INTERRUPT_FLAG);
Once this is done, I can enter user mode using a single sysret instruction.
This instruction uses the rcx register to store the userspace entry point
and the r11 register to hold the new flags upon entering.
A specially crafted thread entry point to enter into user space will be covered
later.
To use this, I need to load a user space executable. My kernel loads static ELF64 executables, and the loader implementation is almost entirely based on the format's description on Wikipedia.
Loading a static executable involves the following steps:
- Validating the ELF header (checking the magic and executable type matches is expected)
- Using the ELF header to locate the program headers.
- Use the information in the program headers to load the program segments into memory.
The program headers contain information to load the actual program segments in the executable. A program header entry looks like this:
#[repr(C)]
pub(super) struct ProgramHeaderEntry {
pub(super) segment_type: u64, // contains both p_type and p_flags
pub(super) offset: u64,
pub(super) virtual_address: u64,
pub(super) unused: u64,
pub(super) image_size: u64,
pub(super) mem_size: u64,
pub(super) align: u64,
}
The segment_type field actually contains to 32-bit fields inside:
let segment_type = header.segment_type as u32;
let segment_flags = (header.segment_type >> 32) as u32;
We filter for headers that have segment_type == 1 (P_LOAD) as they indicate
segments to actually load into memory.
let executable = (segment_flags & 1) > 0;
let writable = (segment_flags & 2) > 0;
let readable = (segment_flags & 4) > 0;
The segment flags tell us whether the segment is executable, writable and readable, which can be applied to the actual memory mappings.
To create these mappings, I allocate new physical frames, and then
map these to the pages behind the address range virtual_address..virtual_address+mem_size.
Note that mem_size can differ from image_size, which is the size of the
data to copy. This is used by the exectuable for the .bss section
(storing uninitialised variables), to inform the loader to reserve space
for these variables but not actually copy any data into it.
Next, I allocate the stack. The contents of the stack on program
initialisation is defined by the System V ABI in Section 3.4.1 Initial Stack and Register State.
This involves allocating:
- An information block (containing argument strings, environment strings)
- Auxiliary variables (used by libc for things such as TLS (thread local storage), however I removed any auxiliary variables after not having any success with setting this up)
- Pointers to environment variables (null since I don't support environment variables yet)
- Finally,
argcand the argument pointers:- The argument pointers point to the argument strings in the information block, since the SysV ABI expects the argument array to actually be contiguous
The userspace entry point (_start) actually retrieves these values from the stack, and passes them to main as int argc and char** argv.
The char** argv actually points to the contiguous array of argument pointers on to the stack, and each char* entry points to a null-terminated string in the information block.
System calls
System call handler
I'll now describe the handle_syscall function from earlier.
This uses Rust's naked functions feature
to create a bare assembly handler which doesn't include the normal function prologue and epilogue
generated by the compiler.
What's important to note is that the syscall instruction doesn't change the current stack or save
any registers from the calling function. Unlike interrupt handlers, the CPU doesn't do any of this
automatically. Instead, the stack switching has to happen manually.
To understand the desired semantics of a system call, the System V ABI can be consulted. In Section A.2.1, the system call interface for Linux is listed as an informative appendix.
My system call interface is very similar except that my syscalls are limited to 4 arguments instead of 6.
At this point, it’s important to understand the semantics of a sysv64 function call. These are the callee-preserved
registers for the System V ABI:
rflagsrbxr12r13r14r15rbprspWhat this means is that upon the function return, the contents of these registers should be the same as they were when called. Any other registers can be freely modified, and if the caller needs to keep the values, they should be saved before calling the function.
My system call interface follows these semantics for preserving of registers. This differs from the Linux
kernel, which preserves all registers except rcx, r11 and rax (at least according to this non-normative section of the ABI).
The main part of the system call handler is as follows (split up and as excerpts):
- The syscall handler saves
ripintorcx, andrflagsintor11. These values are used bysysretto return to userspace, so they are saved to the stack. I also saverbpandrbx, which will be used soon.
push rcx
push r11
push rbp ; will store old sp
push rbx ; will store new sp
- To switch stacks, I need to get the current thread's kernel stack. Currently, this involves a separate function call to some Rust code
which gets it from a
PerCPUstruct (which is itself a wrapper around anUnsafeCellbecause I don't have multiple processor support yet). I wrote this code before I knew aboutFSGSBASEwhich allows code to set the base of thefsandgssegments. Since these are per-processor, they can be used to store information such as the current kernel stack to be accessed without a function call. But because I do use a function call, I need to backup the syscall arguments, since they are in caller-saved registers. After the function call, I userbxto store the new stack, allowing for the syscall params to be restored.
push rax ; syscall number
push rdi ; arg0
push rsi ; arg1
push rdx ; arg2
push r10 ; arg3
call get_kernel_stack ; Return value is now in rax
mov rbx, rax ; RBX = new sp
; Restore syscall params
pop r10
pop rdx
pop rsi
pop rdi
pop rax
- Switch kernel stacks.
mov rbp, rsp ; backup userspace stack
mov rsp, rbx ; switch to new stack
- Call an inner function to handle the system call in Rust. To do so, reshuffle the arguments to follow the sysv64 calling convention.
push rax ; syscall number
push rdi ; arg0
push rsi ; arg1
push rdx ; arg2
push r10 ; arg3
; Pop to follow normal sysv64 calling convention
pop r8
pop rcx
pop rdx
pop rsi
pop rdi
call handle_syscall_inner
- Finally, return from the system call. The return value is now in
raxfrom the previous function.
mov rsp, rbp ; Restore userspace stack
pop rbx
pop rbp
pop r11
pop rcx
sysretq
System call implementation
From here, most system calls are not particularly complicated. I've implemented
check_addr and check_buffer utilities to ensure that pointers and buffers
passed to system calls actually point to lower‑half memory. However, I don't
have any validation past this, so a process can easily crash the kernel
by passing it an invalid pointer.
I've implemented these system calls:
readwriteopenclose(a no-op for now)exitarch_prctl(I used this when trying to integrate the musl libc. I'm using my own pseudo-libc for now, since that was taking too long to integrate.)execvebrkforkwaitid
Kernel Multithreading
Kernel multithreading is the prerequisite which allows for preemptive multitasking of userspace threads. To be able to switch between threads on a timer interrupt, it is far easier to just swap out the kernel context in a fairly controlled way compared to having one kernel thread somehow returning to different userspace stacks. Almost all kernels use this approach of having one kernel-stack per userspace thread.
Context switching
Once a thread is in kernel mode, the userspace stack and saved registers live at the bottom of the kernel stack (placed there by the system call handler to return to later). This means that to switch between threads, only the kernel stack needs to be swapped out.
Take another look at the callee-preserved registers:
rflagsrbxr12r13r14r15rbprsp
To actually execute ret from a function and continue executing the rest of the
thread, these are the only registers which need to be saved. Note that rip
is not on that stack, since the processor will jump back to the return
address that is on the stack. Thus, a "context switch" involves saving and
swapping out these values to switch between threads.
I found two approaches to this.
- xv6's approach pushes all of these values (except
esp) to the stack, and then using the stack pointer as the only thing that needs to be swapped when context switching - Redox's approach uses a struct containing all of the callee-saved registers, and then directly swaps from this struct when context switching
xv6's approach is elegant because it stores context in a single value (esp which is the 32-bit equivalent of rsp).
However, to create a new context, a stack must be constructed manually. I didn't like this, so I chose Redox's approach
which allows for easy changing of these registers. Being able to change these registers directly also proved useful
for both fork() and exec().
For the actual assembly to perform this swapping of contexts, I use Redox's x86-64 switch_to handler (with some modifications).
Scheduler
To decide what threads to run, I wrote a round-robin scheduler.
My scheduler has a main queue called READY, where Arc<Mutex<Thread>>s get
added to. The scheduler picks the next thread to switch to by popping the front element
on this queue. If there are no such elements, then it switches to an idle thread (which halt loops).
The arrangement of locks in here is also interesting. As well as a Mutex on each of the threads,
there is a global mutex surrounding the READY queue. Since queue operations may happen inside
an interrupt handler (for example the pre-emptive multitasking caused by the timer interrupt),
interrupts must be disabled when handling this queue to avoid deadlock. After the context switch operation,
I must manually release the lock on the previous thread in switch_finish_hook (Rust code called by context
switch). This code also sets the page-table mappings for the new thread, and sets the IST such that interrupts
will be handled by the current kernel thread if they occur in user-mode.
One thing to note is that my yield_execution does not return the current thread to the queue. This is useful
for cases where the thread has to wait for something, where the thread itself can be pushed to a different queue,
and returned to the READY queue when the operation is done. This is used for both keyboard input and waitid.
For preemptive yields on a ready thread, a wrapper yield_and_continue can be used to requeue the current thread to
READY, and then yield.
execve()
For the most part, execve is a system call wrapper around the behaviour I already built for ELF64 loading.
Since execve overrides previous mappings, I added code to clear the entire lower half of page-table mappings
before creating any new ones.
Additionally, to reset the thread to begin at the desired entry point, I use a
neat hack. The execve code modifies the context struct itself (which is just a
struct of callee-saved registers), to store the userspace entry point and
initial stack pointer. Then, I set the kernel stack (which is itself allocated
on the kernel heap), to have a single element (a pointer to the
enter_userspace trampoline). Then, when the context switch calls ret, it
will return to the trampoline as if it was called from there. Once in the trampoline,
the user space stack and entry point can be moved into the appropriate registers for
sysret, now returning from the system call in a completely different process.
fork()
This system call was quite challenging to implement. It would have been easier just to spawn a fresh process (like some modern kernels), but I wanted to understand how it works.
Attempt 1: Cloning the kernel stack
Initially, I thought I'd implement this by cloning a thread struct, but changing the parent process to point to a forked process.
The general steps for this would be:
parent_pid = get_pid()
yield_execution()
if get_pid() == parent_pid() {
// Fork hasn't happened yet
child_pid = fork_process()
child_thread = clone_current_thread() // this would clone from the last yield point, so child execution would start from there
set_thread(child_pid, child_thread)
enqueue(child_thread)
return child_pid
} else {
return 0
}
I started implementing this, as it would avoid having to write more assembly to create a custom return for fork().
However, I soon realised that I would have to clone the kernel stack to do to this. This is problematic as I have
the kernel stack allocated on the heap (which is itself problematic for different reasons), which is shared between
all kernel threads.
Cloning the kernel stack seemed much more complicated then just writing the assembly returns, so I decided to go for that approach.
Attempt 2
First, we fork the page table. This involves recursively (4 levels) cloning any pages that were user‑accessible and present. Any kernel mappings could be safely shared.
Then, I assign the frame of the level 4 page table to this process, so that it
can be loaded into the cr3 register by switch_finish_hook.
Now that the new process has been created, the parent thread can easily return the child PID. However, the child process needs to somehow return to the same place, but returning 0. Kernels like xv6 do this by assigning to the trapframe (registers saved by the CPU when entering the interrupt handler).
However, in x86-64, syscalls don't have a trapframe! I couldn't find
any information on implementing fork() with the sysret instructions x86-64.
To solve this, the information needed to return to userspace can be pushed on
the stack manually. The base of the kernel stack is stored in the Thread struct,
and since the kernel stack is empty at the start of a syscall, this can be easily
located.
push rbx
push r12
push r13
push r14
push r15
push rbp
call handle_syscall_inner
Note the omission of rsp here, since the kernel stack is changing anyway. The purpose of preserving
these registers is that some important information (eg: location of old stack and some callee-preserved registers from user space)
are stored there.
let trapframe = current_thread.kstack.last_chunk::<6>().unwrap();
// What we pushed last will have the lowest address (first in our slice)
thread.context.rbp = trapframe[0];
thread.context.r15 = trapframe[1];
thread.context.r14 = trapframe[2];
thread.context.r13 = trapframe[3];
thread.context.r12 = trapframe[4];
thread.context.rbx = trapframe[5];
These 6 registers can be transferred into the new thread using the Context struct.
Then, the fork trampoline simply clears the rax (return value) register and jumps to the normal
syscall return sequence.